What bugs are agents generating? How does vibecoded software break? Where is automated code review coming up short? Is each bug a random oneoff, or can we characterize clear patterns? Are engineers at different companies creating the same few bugs over and over?
To answer these questions, we took 1,000 example bugs from 99 customer codebases and clustered them.
Same mistakes across codebases
We started with 1,000 bugs, each flagged by Detail and subsequently fixed by the customer. We rewrote each bug into a language-agnostic and company-free description of the specific mechanism of the bug, then embedded and clustered those descriptions to group bugs by how they fail.
The first thing we noticed was that 70% of the bugs fell into a small number of clusters. A short list of 21 mechanisms described 70% of these bugs. These same 21 mistakes are recurring hundreds of times across a diverse set of software products.
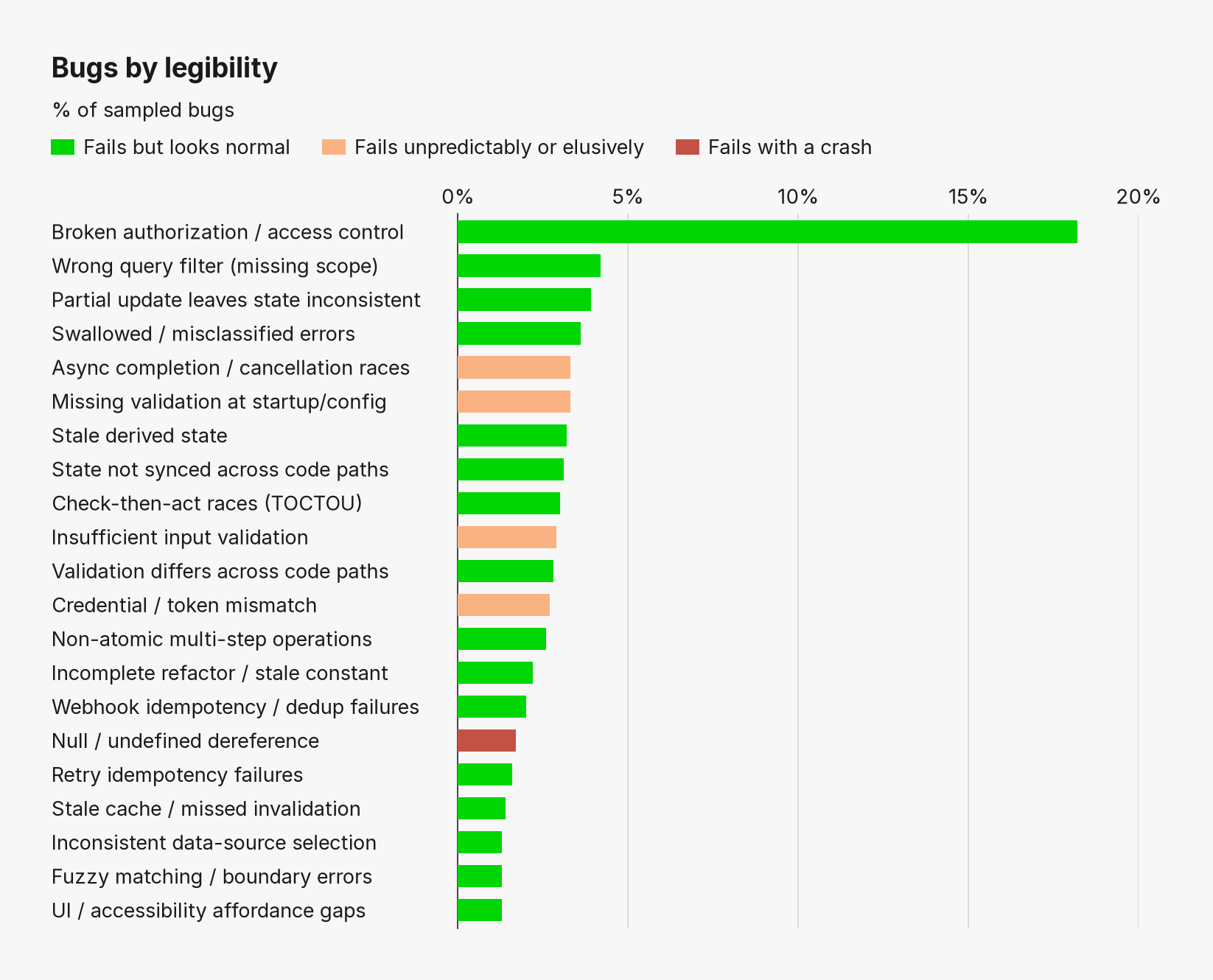
We were surprised to find that the “usual suspects” were very low on the list. For example, null pointer exceptions used to be called the “billion-dollar mistake” , but they made up only 1.7% of the corpus.
If we project these clusters into a low-dimensional space, we can very coarsely map out the space of common bugs. The two most important axes are “authyness” – do the bugs relate to end users improperly accessing information? – and “race-condition-ness” – do the bugs require a non-obvious sequence of events in order to surface?
Bug legibility
What these categories all have in common is that they’re bugs you wouldn’t notice when smoke-testing features in isolation. They aren’t immediately “legible” to the agent writing the code or the engineer testing out a new feature.
An extreme example would be a missing auth check, which is by far the most common category in the corpus. These bugs are bona fide vulnerabilities, not just bugs, but they fail by allowing access they should block, a typical user wouldn’t notice them. Nor would an engineer building a feature, unless they specifically thought to test an auth case that shouldn’t work. These bugs are only visible later, when a hacker finds them, or when a customer notices that the permissions in a SaaS product don’t work properly and a lot of customer trust is lost all at once.
Race conditions, incomplete updates to database state, and inconsistencies across different parts of an app are all similarly illegible. Race conditions can be tricky to reproduce, and most manual QA is single player, so they slip through to production. Detecting inconsistent state-handling requires careful testing across broad surface area, not specific to any one feature an engineer is working on, so it’s similarly easy to miss.
In retrospect, these bugs shouldn’t surprise us, given how software is produced right now. For a bug to get merged, it needs to slip past the engineer and the AI that co-created it, then past linters and any relevant tests, and then past code review. Many of these bugs persisted in production too, either slipping past users or too hard to reproduce, until Detail finally detected them and a customer subsequently fixed them.
Put another way: the bugs that reach production right now are rarely crashes; rather, they’re application behavior that’s clearly broken once you see it, but you might not see it if you don’t look for it.
Making illegible bugs legible
We can beat these categories of bugs. For a small application, it can help just to know what to look for when doing manual QA. (Or, when asking an agent to do our QA for us.) If we’re going to prevent these kinds of subtler defects across a complicated product, we need to do two things:
- Make these bugs more visible to the agents we have today. This is a question of code architecture. When designing a piece of software, one of the most important questions to ask is how to make it obvious to agents whether or not it’s working correctly.
- Build agents that are better at finding bugs. We find patterns like these across thousands of codebases, and we use them to build an agent that’s extremely good at finding the bugs that agents, and especially code review, consistently miss. If you’re interested in this problem, we would love to talk to you.
An example of an architecture pattern that makes bugs much more legible is “denial by default”: make the absence of an explicit grant mean “no access” so that a forgotten authorization check blocks a request instead of allowing it. If you architect your backend endpoints this way, bugs that would leak data silently will instead fail loudly, where ordinary testing can catch it.
Try it
If you’d like to see what’s hiding in your own codebase, the first scan is free. Sign up here.
How we grouped the bugs
Sample. 1,000 bugs from 99 customers over the last two and a half months, capped at 5% per company so no single customer skews the mix, and anonymized. Every bug was flagged by Detail and then fixed by the customer’s engineers. The most common language in the sample was TypeScript. Almost all customers use at least one automated code review system, and some use multiple.
Method. Claude Haiku 4.5 rewrote each bug into a code-free, company-free, language-free description of its mechanism. We embedded those descriptions with two models, OpenAI’s text-embedding-3-large and Google’s gemini-embedding-001, reduced dimensionality with UMAP
, and clustered with HDBSCAN
, which leaves outliers ungrouped rather than forcing every point into a cluster. Clustering the original bug reports instead recovers language and company, not mechanism. Claude Opus 4.8 then named each cluster after reading a sample of its bugs.
Validation. Normalized mutual information between the clusters and company, repository, or language was low, around 0.14 for language. The two embedding models recovered substantially the same structure. We read blind samples from each cluster to check that the labels fit and the groups hold together as single mechanisms, and reviewed the largest clusters by hand.